
- プログラミングは分からないけど自動化したい
- PowerAutomateの使い方がイマイチ分からない
- メール本文から名前を抽出したい
無料ツールでさらにノンプログラミングで自動化ができるならぜひやってみたい!
この記事では、そんな方に向けてメール本文から名前を抽出する方法を3ステップで説明します。
- メール本文から名前を抽出するフロー
- 文章から文字列を抽出する仕組み
- フローを作る
この記事を読めば、文字列の抽出方法が分かるようになります。
まだPowerAutomateを使った事が無いという方はこちらの記事を参考にしてください。

PowerAutomateはブラウザで操作するのでインストール無しで利用できます。Windows10ではないMacユーザも自由に使えます。




最短?ループ無しの3アクションで抽出するフロー
この項目は手短に文字抽出を行うことが目的で、とりあえず抽出フローのみ知りたいという方向けです。
詳しく知りたい方は次の項目から読んでください。
こちらはループ処理を省略して、メール本文の1アクションを除く3アクションで名前の抽出を行っています。
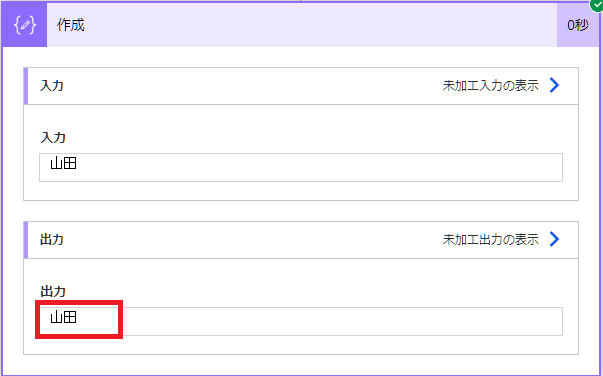
フローを動かすと「山田」が抽出されました。
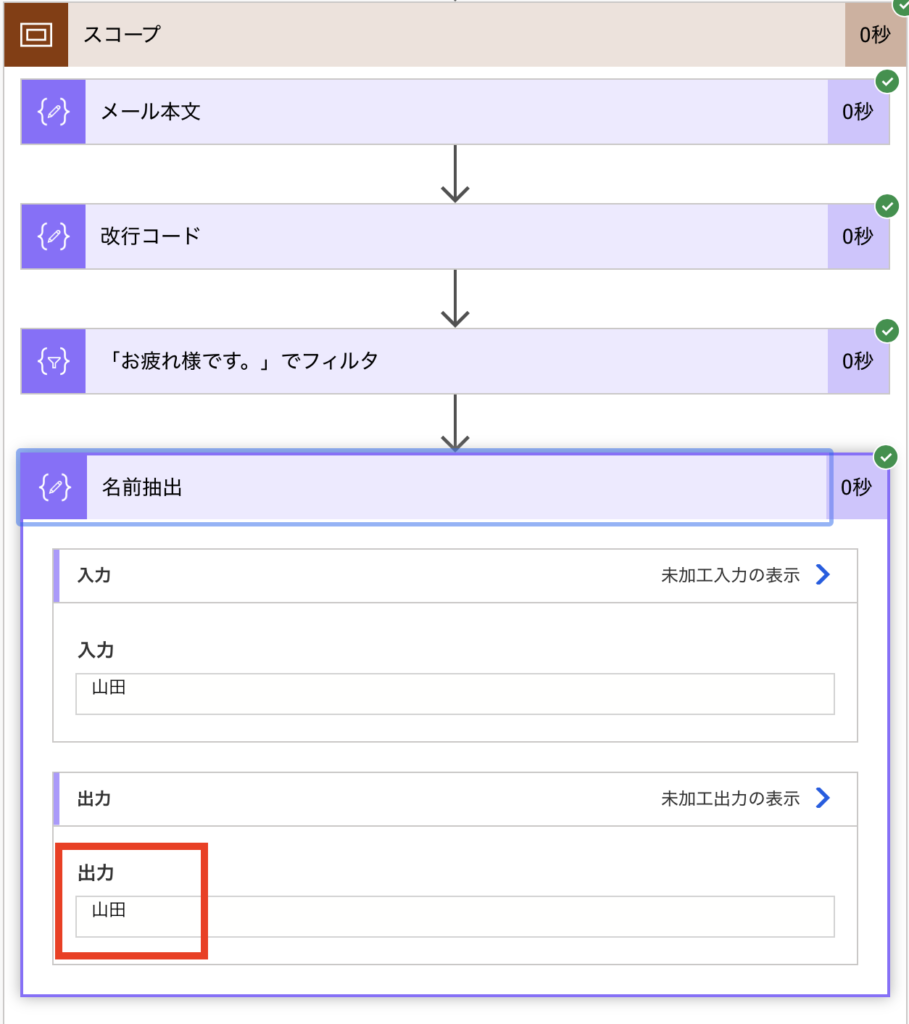
アクションの追加にある「自分のクリップボード」を開いてコードを貼り付けて使ってください。
{"id":"5f45f7dc-238d-401a-8c5a-573bcf394c0a","brandColor":"#8C3900","connectionReferences":{},"connectorDisplayName":"制御","icon":"data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMzIiIGhlaWdodD0iMzIiIHZlcnNpb249IjEuMSIgdmlld0JveD0iMCAwIDMyIDMyIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPg0KIDxwYXRoIGQ9Im0wIDBoMzJ2MzJoLTMyeiIgZmlsbD0iIzhDMzkwMCIvPg0KIDxwYXRoIGQ9Im04IDEwaDE2djEyaC0xNnptMTUgMTF2LTEwaC0xNHYxMHptLTItOHY2aC0xMHYtNnptLTEgNXYtNGgtOHY0eiIgZmlsbD0iI2ZmZiIvPg0KPC9zdmc+DQo=","isTrigger":false,"operationName":"スコープ","operationDefinition":{"type":"Scope","actions":{"メール本文":{"type":"Compose","inputs":"○さん\nお疲れ様です。山田です。\n\n提案書を添付するので確認をお願いします。\n\n以上、宜しくお願い致します。","runAfter":{}},"改行コード":{"type":"Compose","inputs":"@decodeUriComponent('%0A')","runAfter":{"メール本文":["Succeeded"]},"description":"PowerAutomate&Unix=%0A_Windows=%0D%0A_Mac=%0D"},"「お疲れ様です。」でフィルタ":{"type":"Query","inputs":{"from":"@split(outputs('メール本文'),outputs('改行コード'))","where":"@contains(item(), 'お疲れ様です。')"},"runAfter":{"改行コード":["Succeeded"]}},"名前抽出":{"type":"Compose","inputs":"@replace(split(first(body('「お疲れ様です。」でフィルタ')),'。')[1],'です','')","runAfter":{"「お疲れ様です。」でフィルタ":["Succeeded"]}}},"runAfter":{}}}
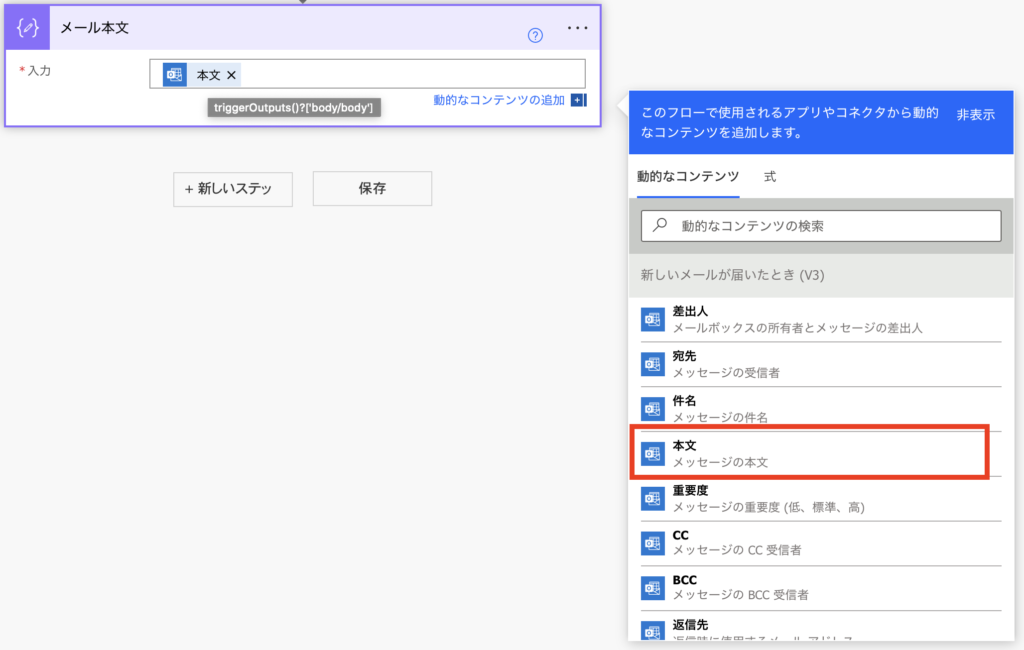
コードを貼り付けしたらメール本文に抽出したいメールデータを入れます。
トリガーが「新しいメールを受信」の場合は「新しいメールが届いたとき」の本文を指定します。
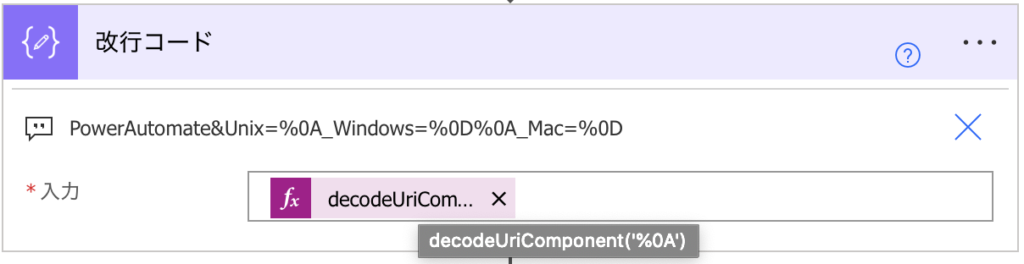
メール本文のデータによって改行コードを変更します。
- PowerAutomateやUnix系 ・・decodeUriComponent(‘%0A’)
- Windows系 ・・decodeUriComponent(‘%0D%0A’)
- Mac系 ・・decodeUriComponent(‘%0D’)
3アクションコピペの設定は以上です。
3アクションの方法は関数を組み合わせているのでコードは読みにくいです。
次の項目からは関数に慣れてない方でも分かりやすいフローを使って説明します。
メール本文から名前を抽出するフロー
今回例として使うメール本文はこちらです。
○さん
お疲れ様です。山田です。
提案書を添付するので確認をお願いします。
以上、宜しくお願い致します。
この文章から山田の2文字を抽出してみます。
動かすフローはこちらです。
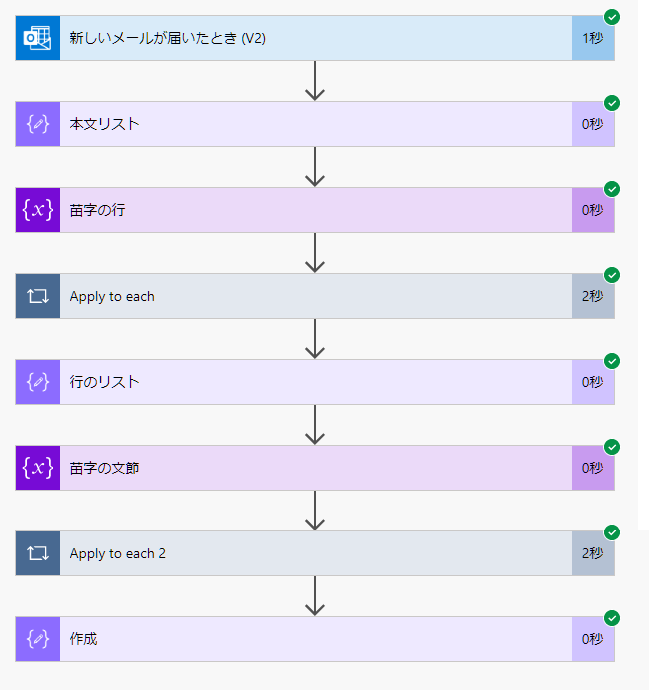
フローの内容は後で説明するので、こんなフローで動くんだ。くらいで見ておいてください。
(1)メールを受信
メール本文を取得しました。
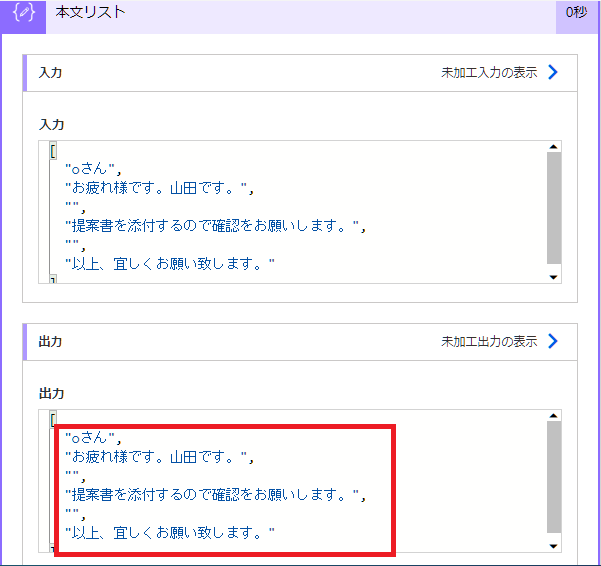
(2)「お疲れ様です。山田です。」を抽出
まずは行を抽出しました。
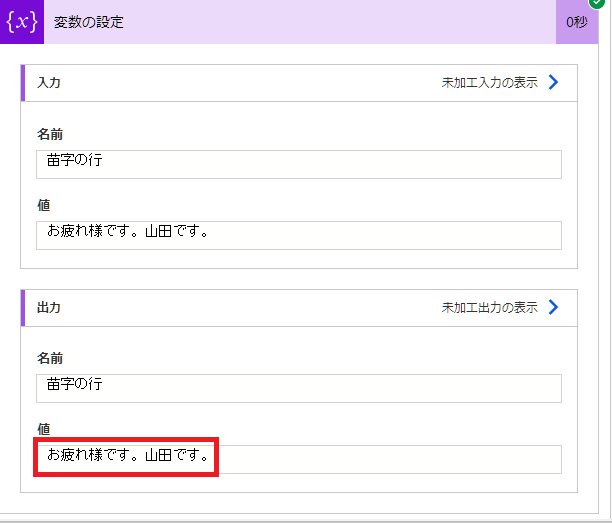
(3)「山田です」を抽出
次に文節を抽出できました。
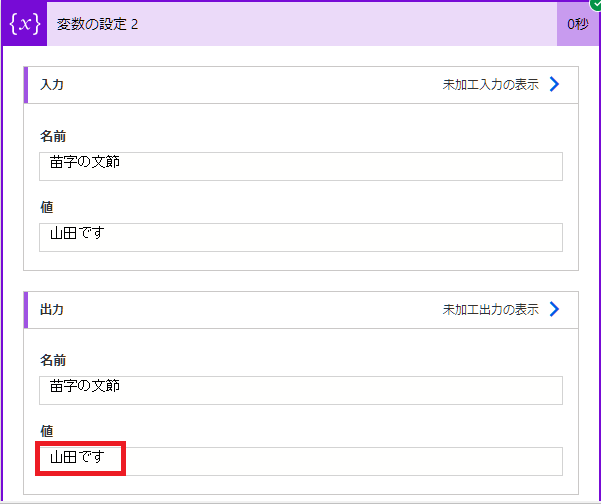
(4)「山田」の抽出に成功
文節からは不要な文字を削除しました。
名前を求める為に使った条件は3つです。
- 行の抽出 「お疲れ様です。」「お世話になっております。」を含む行
- 文節の抽出 「お疲れ様です。」「お世話になっております。」が含まず、さらに1文字以上ある文節
- 名前の抽出 「です」を含む ※削除する
この3つから名前を求めることができました。
動きは分かりましたが、どうやっているのか。その仕組みを次の項目で説明します。
仕組みには重要なポイントが沢山あるのでしっかり見てください。
文章から文字列を抽出する仕組み
分割と検索を繰り返して目的の文字まで到達させます。
実際の段階ごとに表示するとこんな感じです。
最初の本文から・・
○さん
お疲れ様です。山田です。
提案書を添付するので確認をお願いします。
以上、宜しくお願い致します。
行で分割して「お疲れ様です。」で検索するとこうなります。↓
お疲れ様です。山田です。
「。」で分割して「お疲れ様です」以外で検索するとこうなります。↓
山田です
「です」を消すとこうなります。↓
山田
抽出成功!
次は分割や文字を置換する方法について説明します。
こちらにあるPowerAutomateの関数を使います。
- 文字列を分割する・・split
- 文字数を求める・・length
- 文字を置換する・・replace
関数は値を指定すると関数に応じた処理をして別の値を返すものです。
使い方は動的なコンテンツの右にある「式」へ関数とその値を入力するだけです。
例で文字を分割するsplitを使ってみます。値には「’お疲れ様です。山田です。’,’。’」を入れてみます。
split(‘お疲れ様です。山田です。’,’。’)
フローをテストで動かすとこの結果になります。
1:’お疲れ様です’
2:’山田です’
3:”
「。」で分割しているので最後の「。」の後ろにある文字列ゼロの空間も分割されて3番目として出てきます。splitで指定するのは文字列ですが、結果はリスト(=配列)として戻ってきます。
リストは文字列に番号を付けていくつも入れる事のできる箱です。文字列を分割するので元の1つの文字列としては結果を出せません。なので自動的にリストとして出てきます。
リストの使い方ですが、アクションのApply to eachで「以前の手順から出力を選択」にリストを選択します。
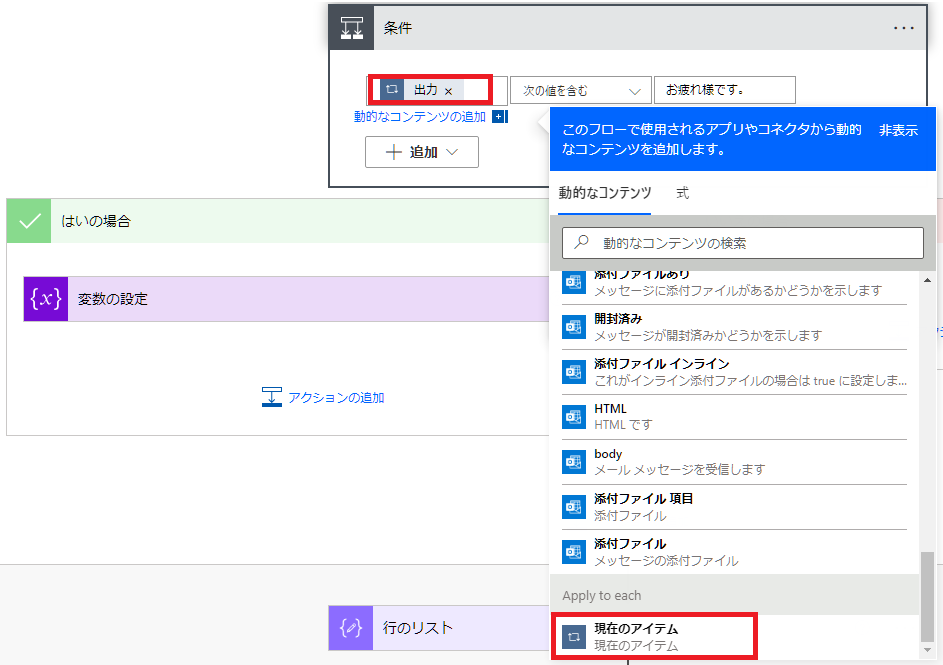
そして動的なコンテンツにある「現在のアイテム」を指定するとリストの値を使えます。
lengthも試してみます。
length(‘です’))
結果は2です。
2
今回はこれらの関数を組み合わせてフローを作っていきます。
フローを作る
今回作るフローです。トリガーを除くと8つのアクションがあります。
今回使うアクションは5種類です。
- アクション:データ操作(本文リスト、行のリスト、作成)
- アクション:変数を初期化する(苗字の行、苗字の文節)
- アクション:Apply to each
- アクション:条件 ※Apply to eachの中にあります。
- アクション:変数の設定 ※条件の中にあります。
使い方は作りながら見ていきましょう。それではフローを作っていきます。
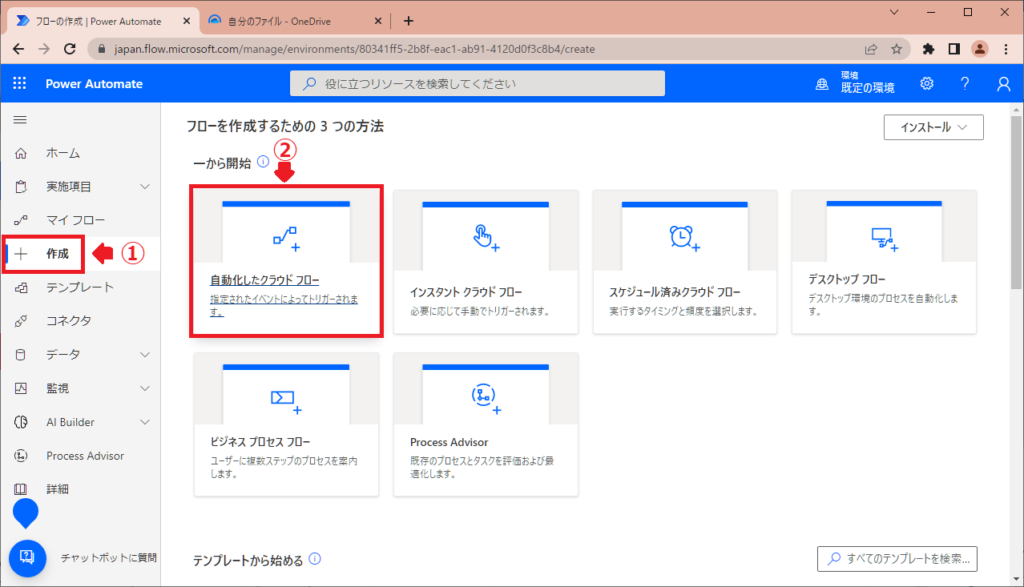
まだ画面を開いていない方はMicrosoftの公式サイトからPowerAutomateを開いてください。
画面左にある作成から「自動化したクラウドフロー」を選択。
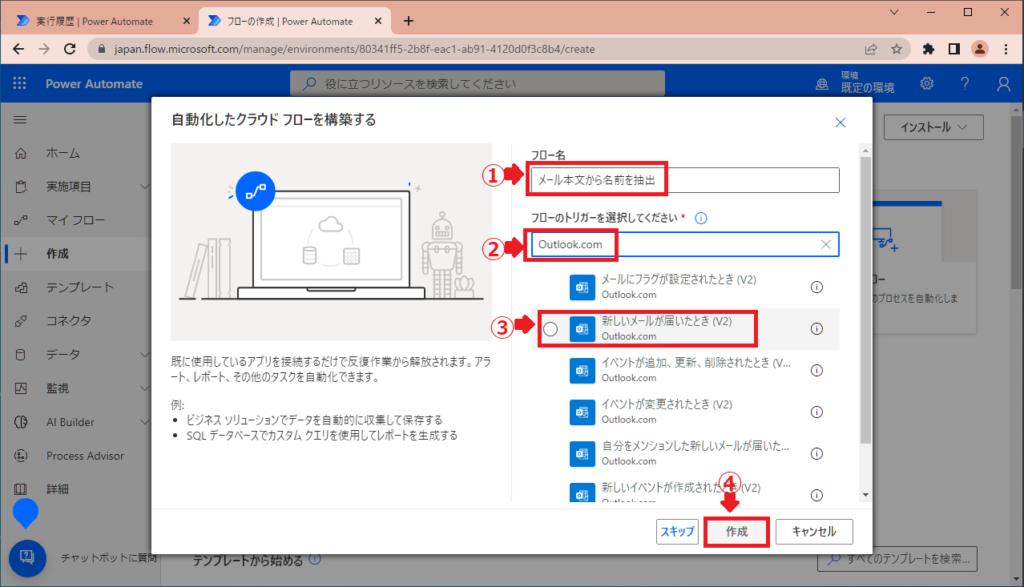
フロー名を入力して「新しいメールが届いたとき(V2)」を選んで作成します。
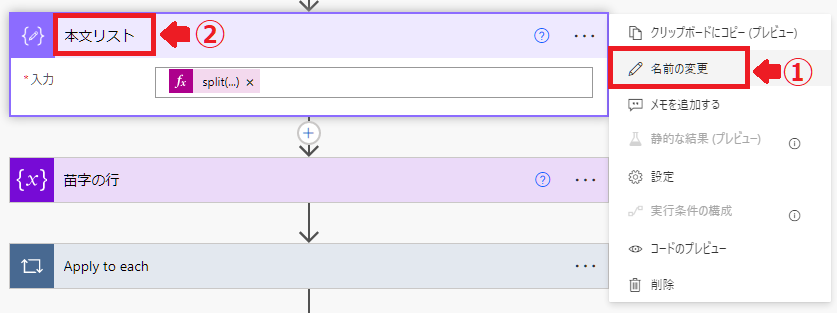
新しいステップからデータ操作の「作成」を選択。

アクションの名前を「本文リスト」に変更
入力には式を設定します。
式:split(triggerOutputs()?[‘body/BodyPreview’],decodeUriComponent(‘%0D%0A’))
メール本文を改行で区切ってリスト化する式です。
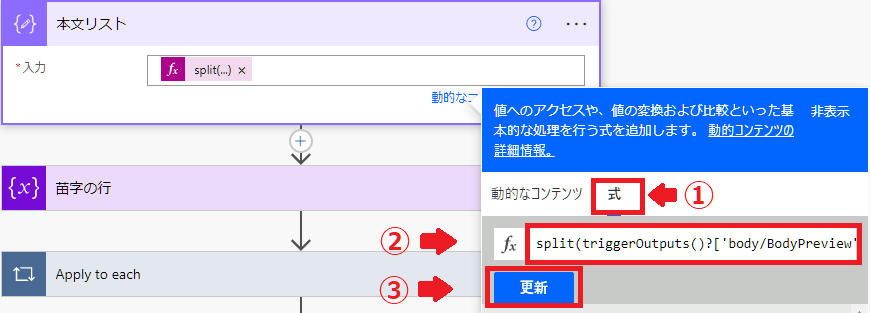
split(triggerOutputs()?[‘body/BodyPreview’],decodeUriComponent(‘%0D%0A’))
- triggerOutputs()?[‘body/BodyPreview’] メール本文を返します。
- decodeUriComponent ()の中にある文字を変換します。 上の式だと’%0D%0A’は’/r/n’になります。
- split ()の中にある文字を分割します。 split(‘てすと1ーてすと2’,’ー’)は’てすと1’と’てすと2’に分けられる。
新しいステップで「変数を初期化する」を選択。

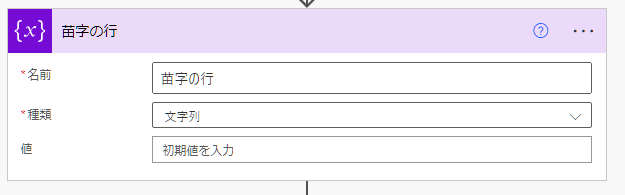
アクションの名前を「苗字の行」に変更して、3か所設定します。
名前:苗字の行
種類:文字列
値 :何も入力しない
※この変数は条件の中で値を設定します。
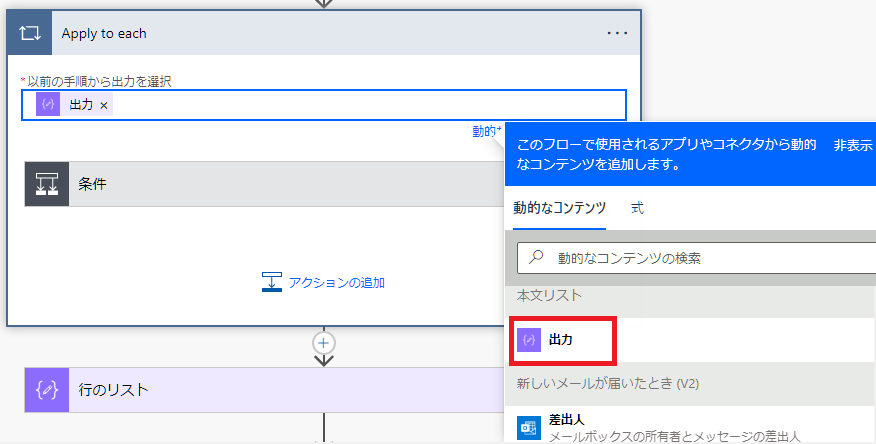
新しいステップで「Apply to each」を選択。

以前の手順から出力を選択して、本文リストの「出力」を指定。
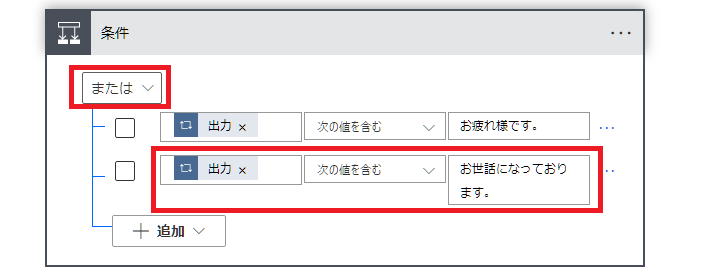
新しいステップで「条件」を選択。

条件を3つ設定します。
左:動的なコンテンツにある「現在のアイテム」
中:次の値を含む
右:お疲れ様です。
追加から「行の追加」を押します。
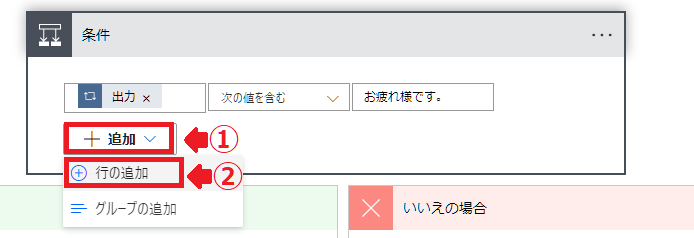
左上が「または」に設定して3か所入力します。
左:動的なコンテンツにある「現在のアイテム」
中:次の値を含む
右:お世話になっております。
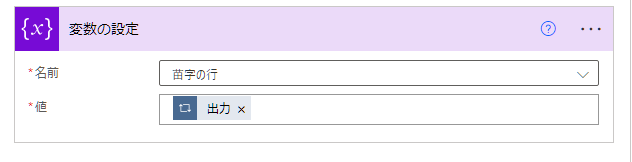
新しいステップで「変数の設定」を選択。

2か所入力します。
名前:苗字の行
値 :動的なコンテンツにある「現在のアイテム」
新しいステップで「作成」を選択。
アクションの名前を「行のリスト」に変更、入力には式を設定します。
式:split(variables(‘苗字の行’),’。’)
この式でメール本文を改行で区切ってリスト化します。
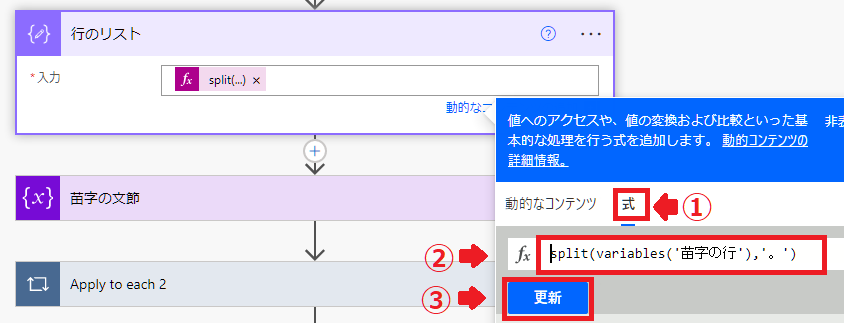
split(variables(‘苗字の行’),’。’)
- variables(‘苗字の行’) 変数の名前’苗字の行’の値を返します。
- split ()の中にある文字を分割します。 split(‘てすと1ーてすと2’,’ー’)は’てすと1’と’てすと2’に分けられる。
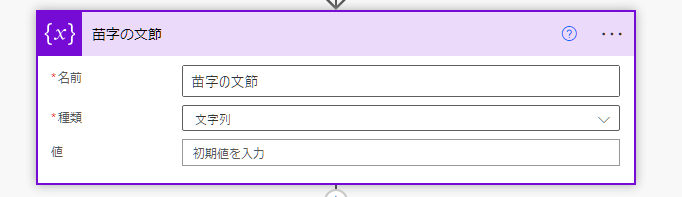
新しいステップで「変数の初期化」を選択。
アクションの名前を「苗字の文節」に変更、3か所設定します。
名前:苗字の文節
種類:文字列
値 :何も入力しない
※この変数は条件の中で値を設定します。
新しいステップで「Apply to each」を選択。
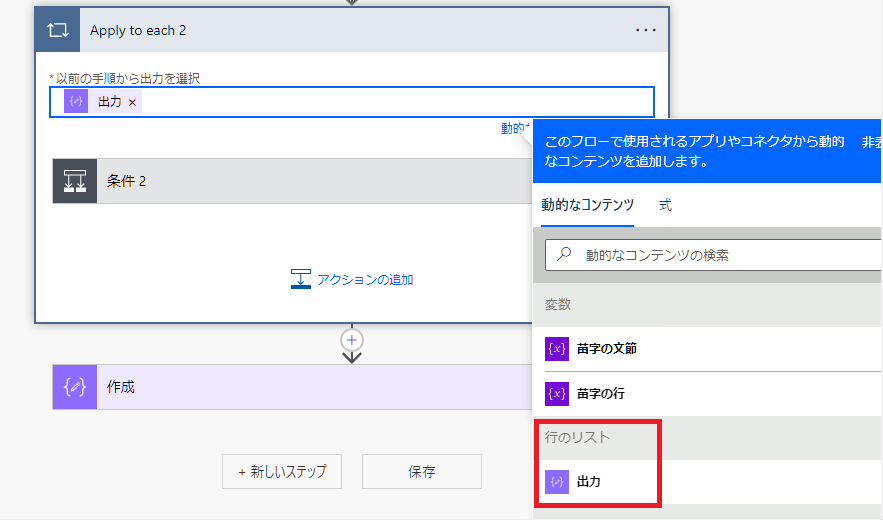
以前の手順から出力を選択して、行のリストの「出力」を指定。
※本文リストの「出力」ではないので注意してください。
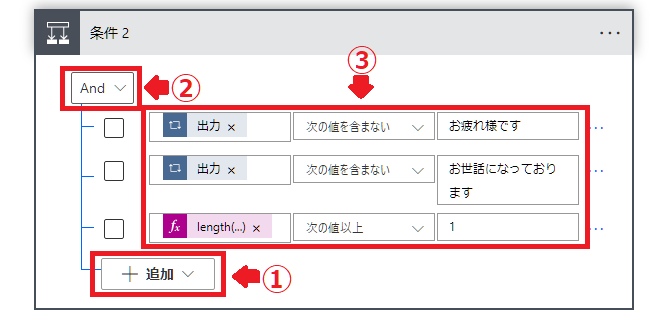
新しいステップで「条件」を選択。
追加から「行の追加」を2回おこない3行ある状態にします。
②をAndに設定。
③を入力します。
1~2行目はAplly to each 2にある「現在のアイテム」を指定してください。

3行目には式を設定します。
式:length(items(‘Apply_to_each_2’))
この式は区切った文節の文字数を確認します。
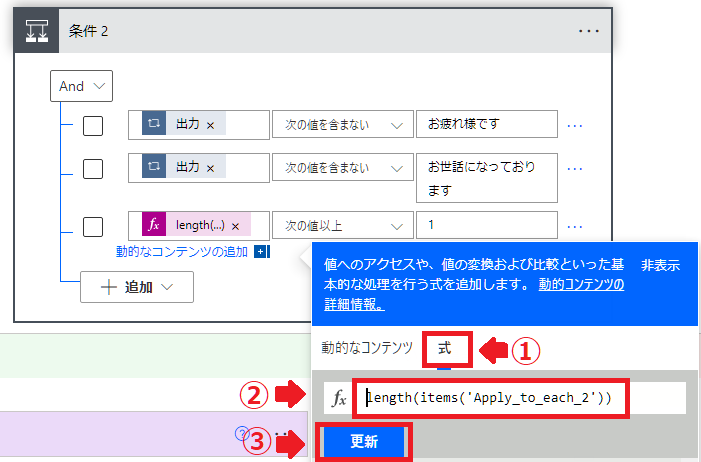
length(items(‘Apply_to_each_2’))
- items(‘Apply_to_each_2’) Apply to each 2で指定したリストの中にある1つを返します。
- length ()の中にある文字数を返します。 length(‘てすと’)は3です。
新しいステップで「変数の設定」を選択。
2か所入力します。
名前:苗字の行
値 :動的なコンテンツにある「現在のアイテム」
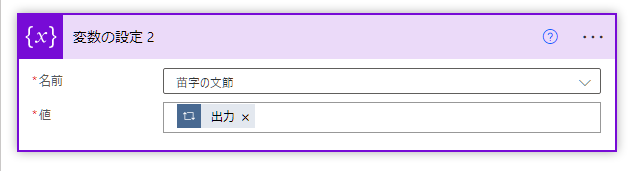
ここで指定する現在のアイテムもApply to each 2の方を選んでください。
入力には式を設定します。
式:replace(variables(‘苗字の文節’),’です’,”)
この式でメール本文を改行で区切ってリスト化します。
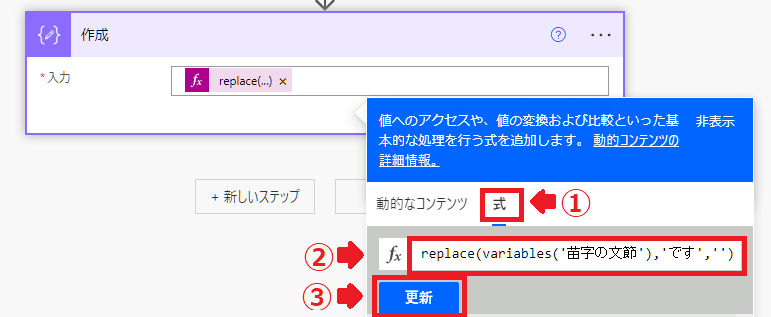
replace(variables(‘苗字の文節’),’です’,”)
- variables(‘苗字の文節’) 変数の名前’苗字の文節’の値を返します。
- replace ()の中にある文字を置換します。 replace(‘てすと1’,’1’,’2’)は’てすと2’になる。
これでフロー完成です。
動かした結果はこちら。
本文リストに受信したメールの本文が入っています。
最後の作成のアクションで「山田」のみに抽出できました。
まとめ
メール本文から名前を抽出する方法を3ステップで説明しました。
- メール本文から名前を抽出するフロー
- 文章から文字列を抽出する仕組み
- フローを作る
文字を抽出するのはsplitと条件の組み合わせです。splitを使うとリスト(=配列)になるのでそこを上手く使いこなすのがポイントになっています。リストが使えると自動化の幅が一気に広がるので、ぜひ身につけてください。
PowerAutomateのおすすめ記事
人気ページ
Apply to eachの使い方
アレイのフィルター処理の使い方
日付関数の使い方
エラーを無視する方法
メールの内容をExcelへ転記
メール本文から名前を抽出
>>PowerAutomateの記事一覧を見る<<
お気に入り必須!公式ページ
Microsoft Power Automate
式関数のリファレンス
コネクタのリファレンス
Excel Online (Business)のリファレンス